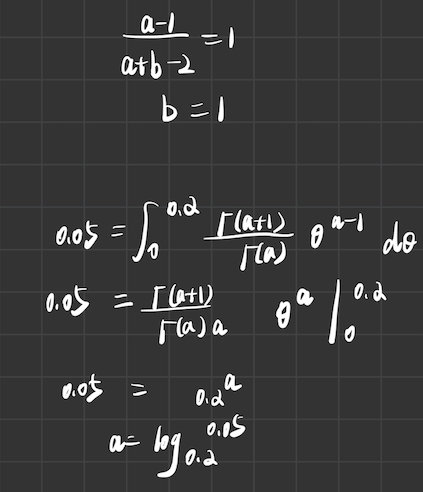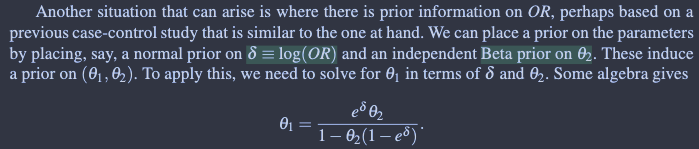Find Jeffreys’ prior for \(\theta\) based on a random sample of size \(n\) when (a) \(y_i|\theta ∼ Pois(\theta)\), (b) \(y_i|\theta ∼ Exp(\theta)\), (c) \(y_i|\theta ∼ Weib(2,\theta)\), (d) \(y_i|\theta\)is negative binomial as in Example 4.3.3.
Answer:
Definte
In general, for a one parameter problem, Fisher’s information is defined to be the expected value of the negative of the second derivative of the log-likelihood. Jeffreys’ prior is defined as being proportional to the square root of the Fisher information.
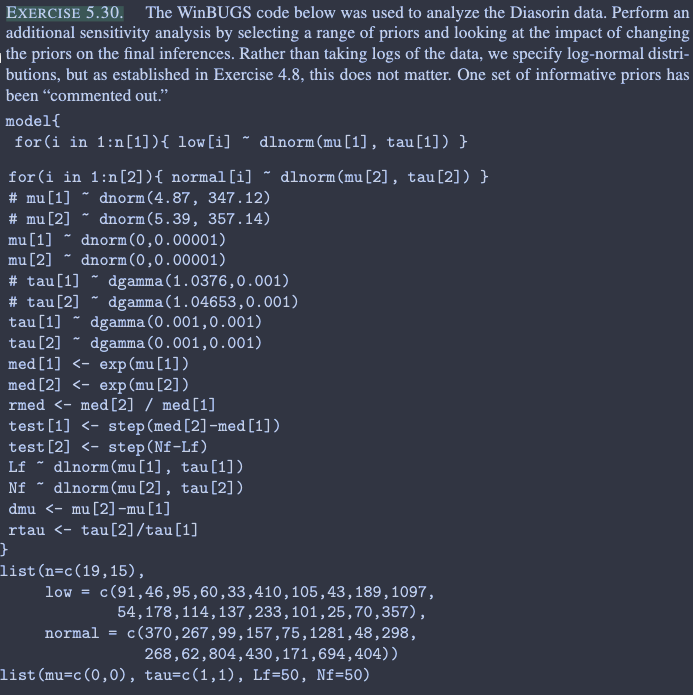
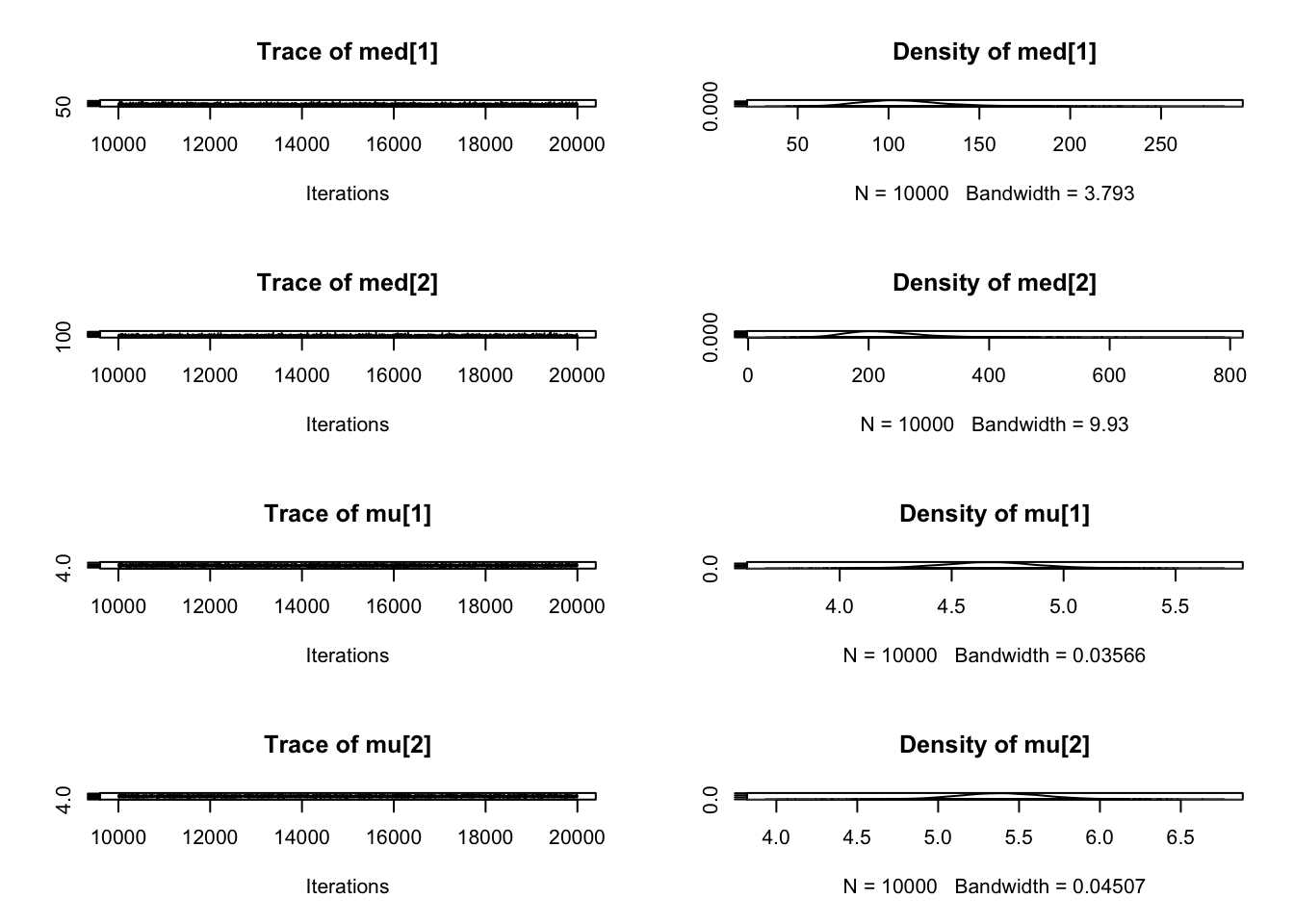
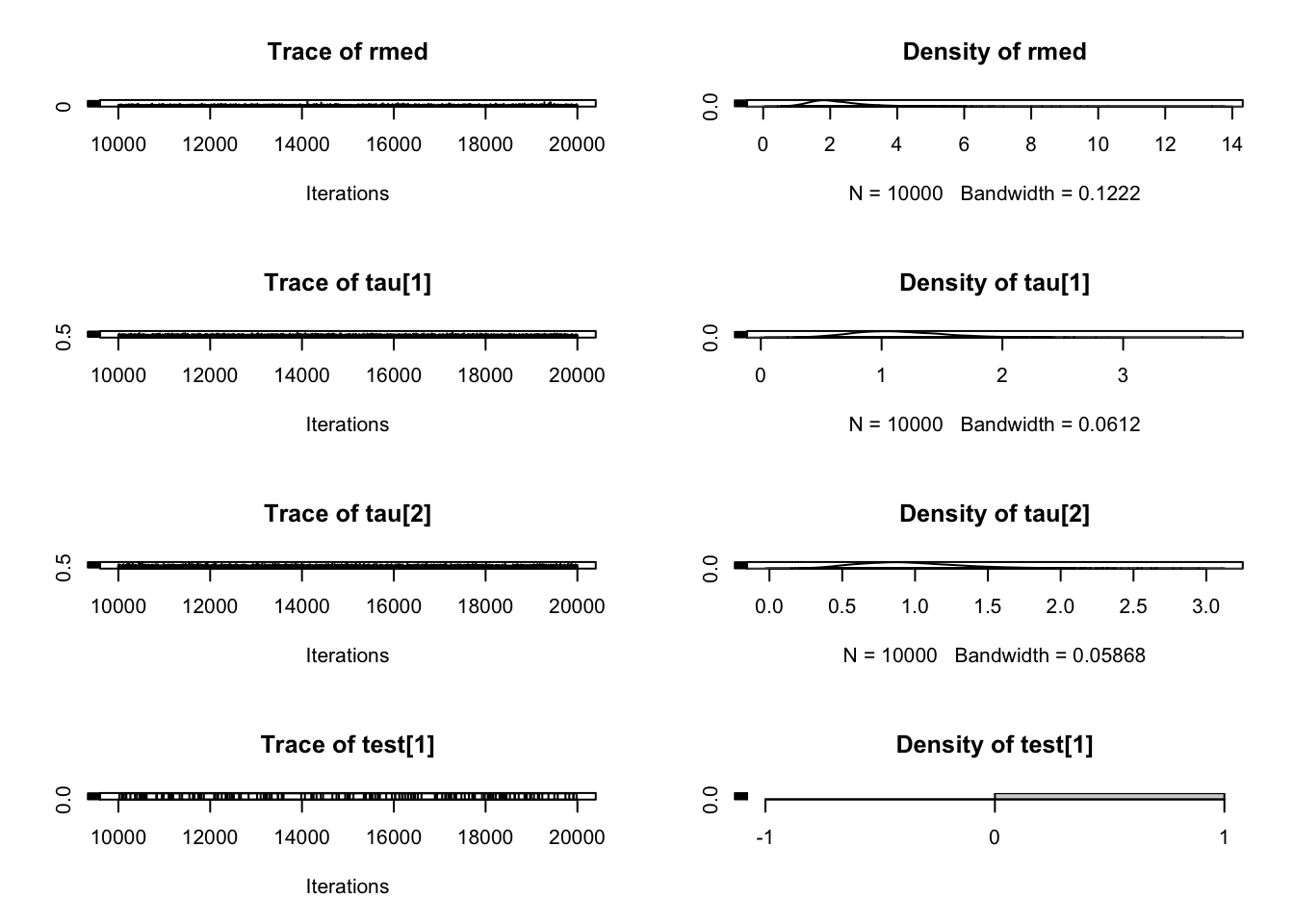
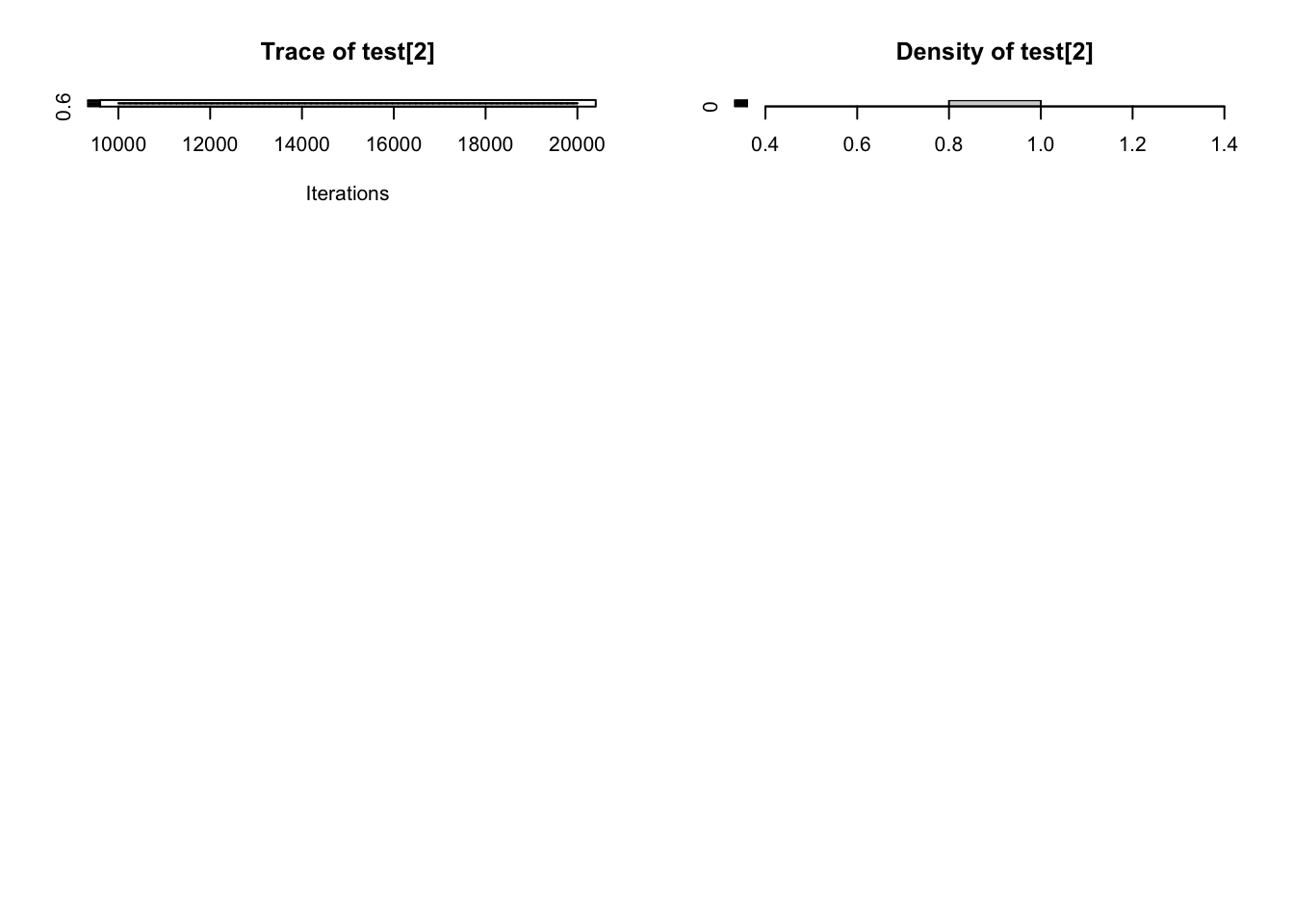
Iterations = 10001:15000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 5000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
9.043e-02 5.781e-03 8.176e-05 1.047e-04
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
0.07956 0.08642 0.09028 0.09423 0.10202
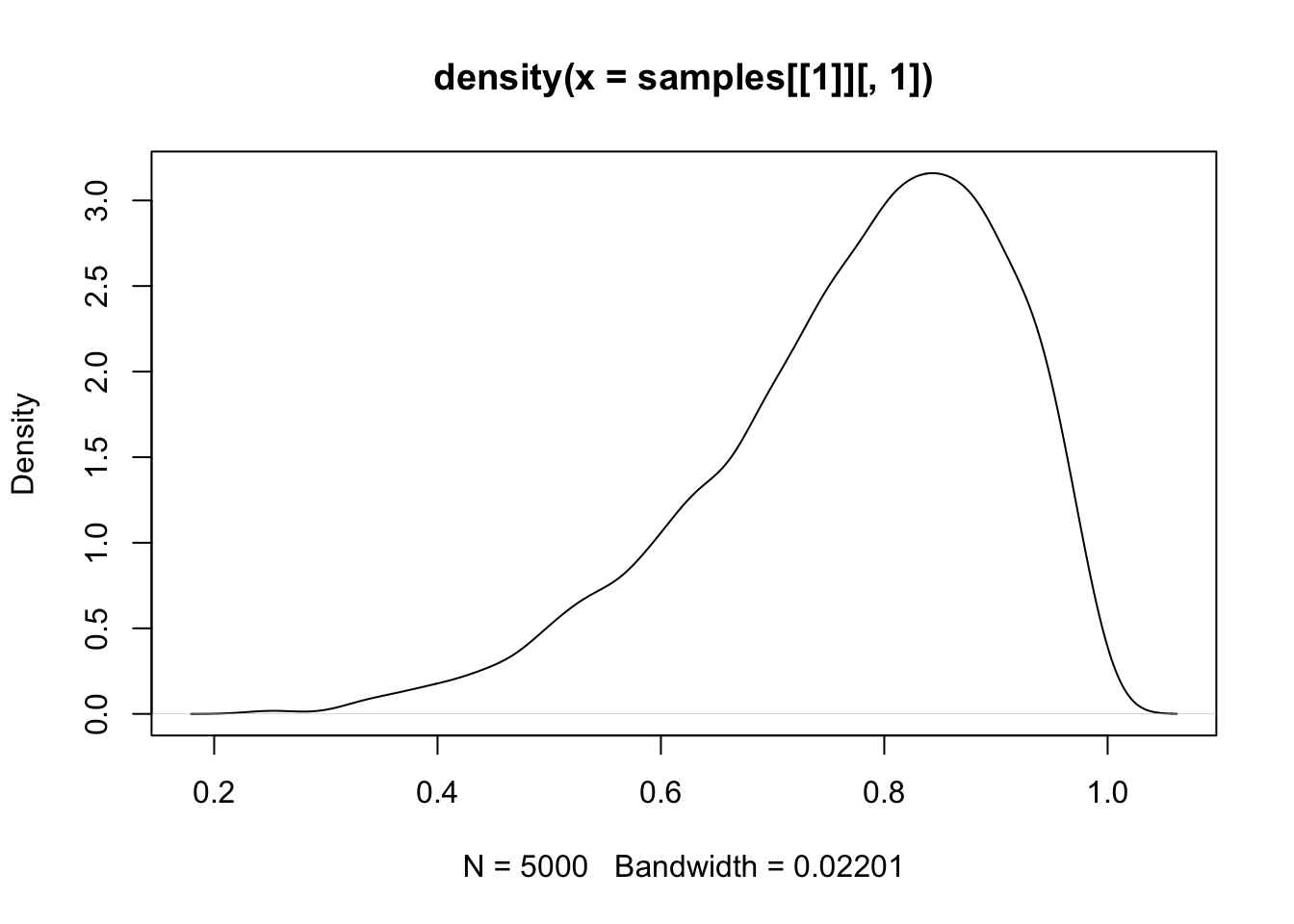
# plot(samples)
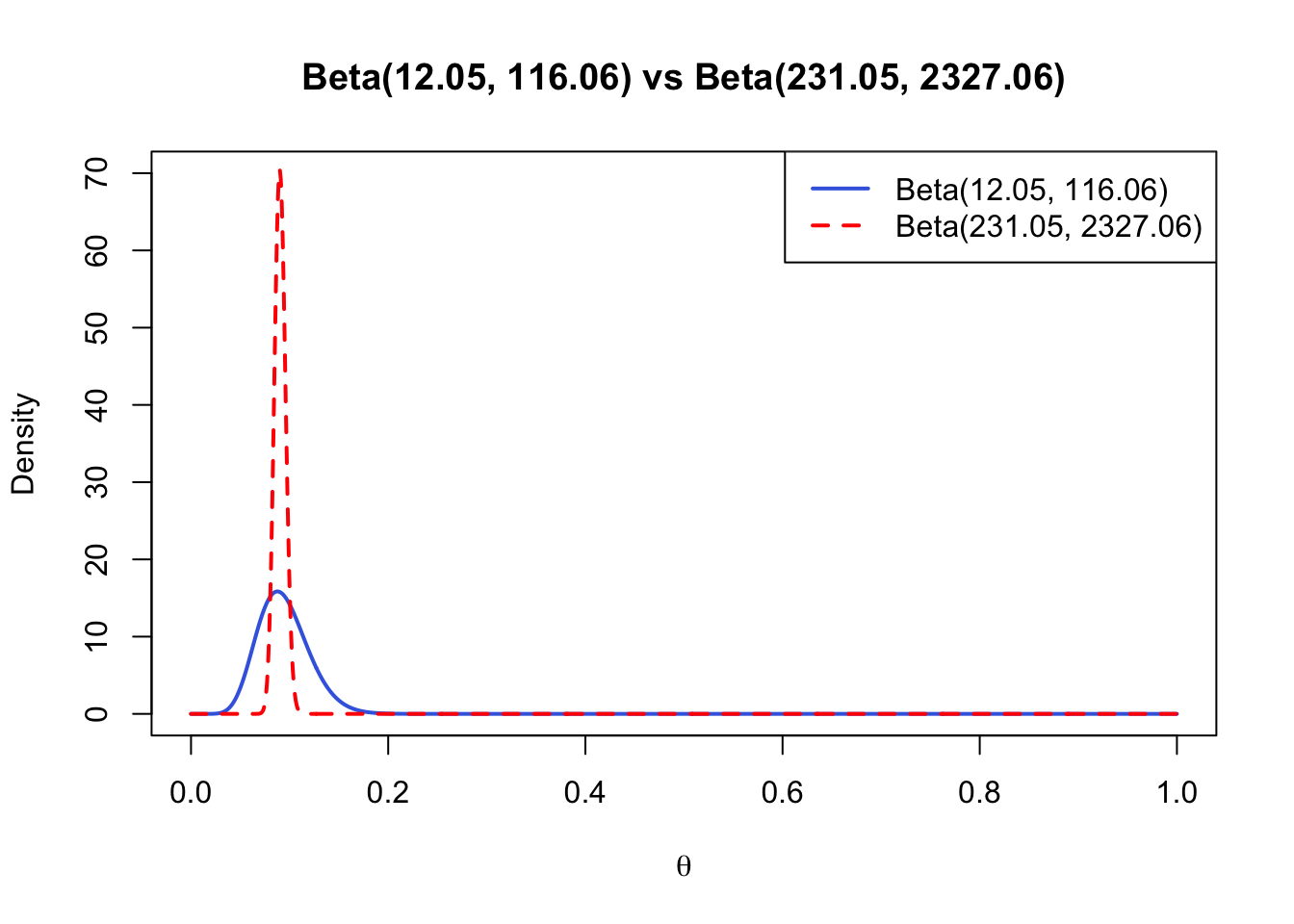
# Plot the Beta(12.05, 116.06) distributionplot(seq(0, 1, length.out =1000), dbeta(seq(0, 1, length.out =1000), 12.05, 116.06), type ="l", col ="#4169E1", lwd =2, main ="Beta(12.05, 116.06) vs Beta(231.05, 2327.06)", ylim =c(0,70),xlab =expression(theta), ylab ="Density")# Add the Beta(231.05, 2327.06) distributionlines(seq(0, 1, length.out =1000), dbeta(seq(0, 1, length.out =1000),231.05, 2327.06), col ="red", lwd =2, lty =2) # Use dashed line type for differentiation# Add a legendlegend("topright", legend =c("Beta(12.05, 116.06)", "Beta(231.05, 2327.06)"), col =c("#4169E1", "red"), lwd =2, lty =c(1, 2))
EXERCISE 5.3.
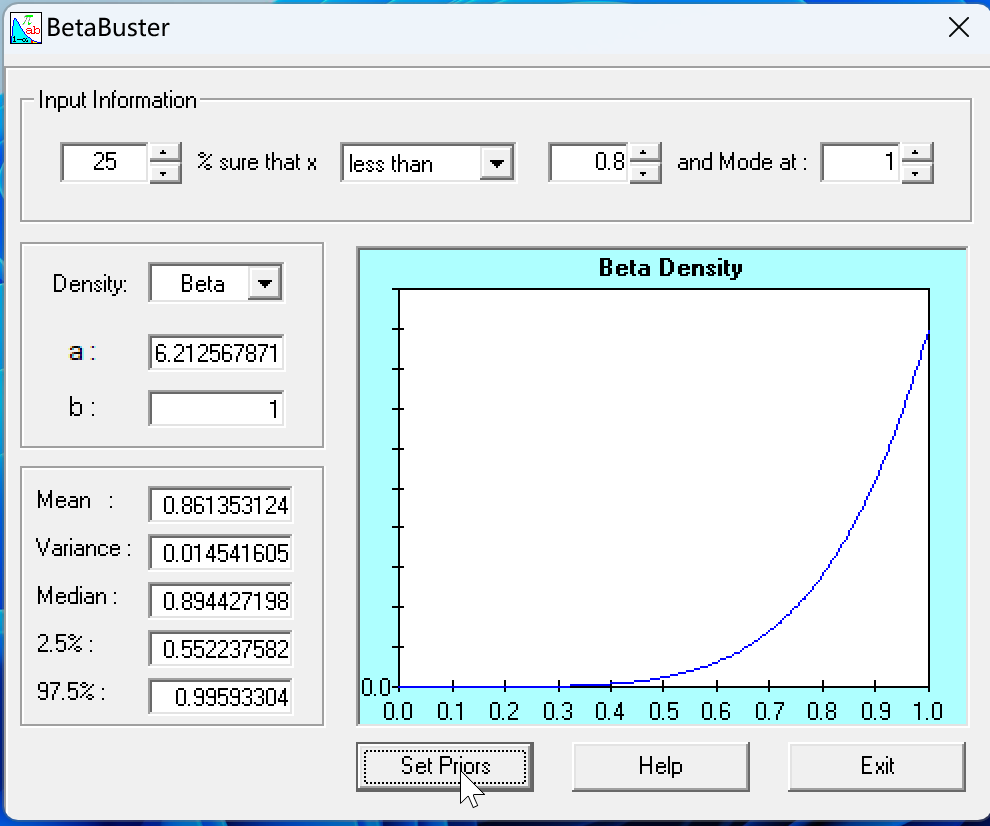
Using calculus, find the mode and 5th percentile of a Beta(10,1) distribution.
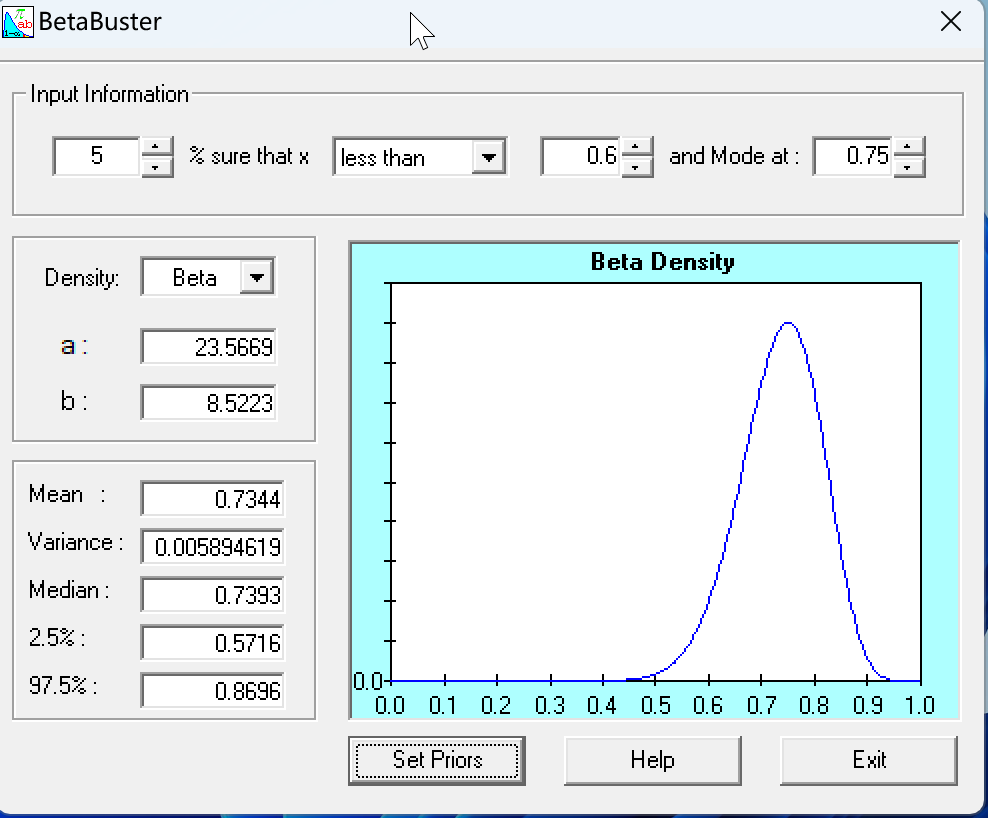
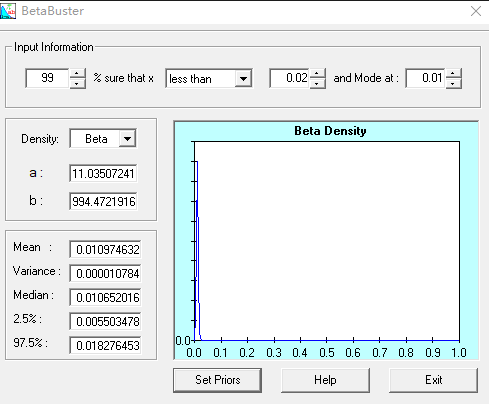
Use BetaBuster to find the Beta(a, b) priors for mode 0.75 and 5th percentile 0.60, and for mode 0.01 and 99th percentile 0.02. What is the Beta prior when the mode is 1 and the first percentile is 0.80?
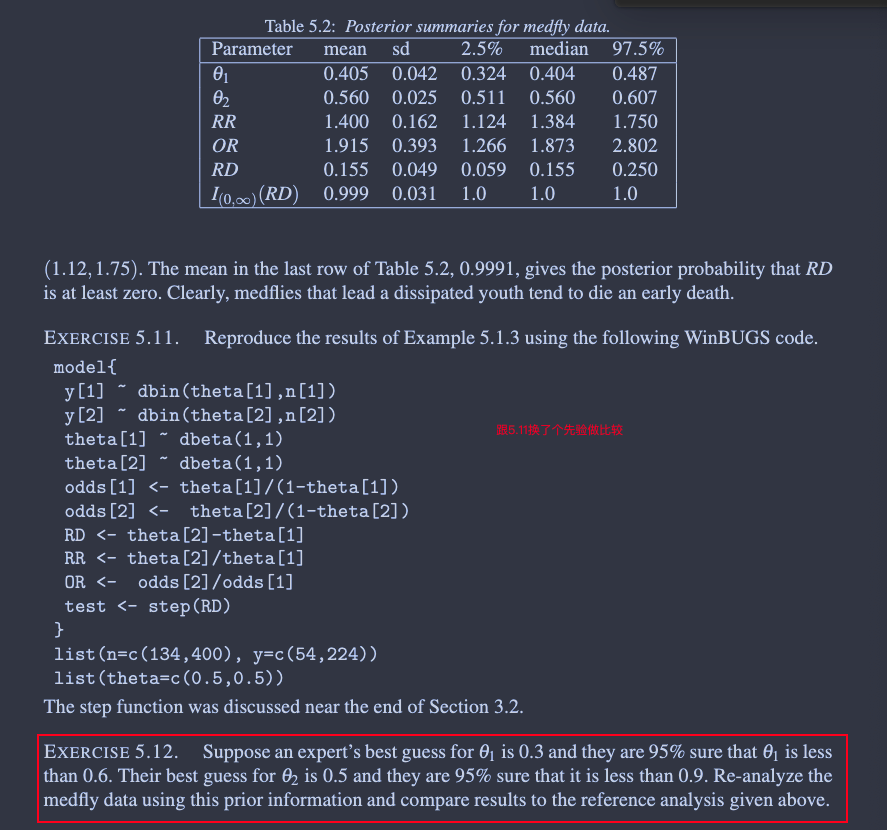
EXERCISE 5.7.
The distributions θ ∼ Beta(1.6, 1) and θ ∼ Beta(1, 0.577) both have a mode of 1. Find Pr[θ < 0.5] analytically for each. Does BetaBuster give the appropriate parameters for the Beta distributions?
Iterations = 10001:15000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 5000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
7.5689 15.6947 0.2220 0.2452
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
0.6377 2.0738 3.9610 7.7736 36.4600
Iterations = 20001:30000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 10000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
12.7363 19.3095 0.1931 0.3205
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
1.270 3.913 7.351 14.303 57.329
Iterations = 20001:30000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 10000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
11.0003 10.9282 0.1093 0.1493
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
0.9082 3.2367 6.9098 14.8292 42.4630
Iterations = 20001:30000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 10000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
5.92988 4.04559 0.04046 0.05042
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
1.598 3.319 4.877 7.301 16.424
Iterations = 20001:30000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 10000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
0.620732 0.201921 0.002019 0.002476
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
0.3131 0.4779 0.5910 0.7305 1.0977
Iterations = 10001:15000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 5000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
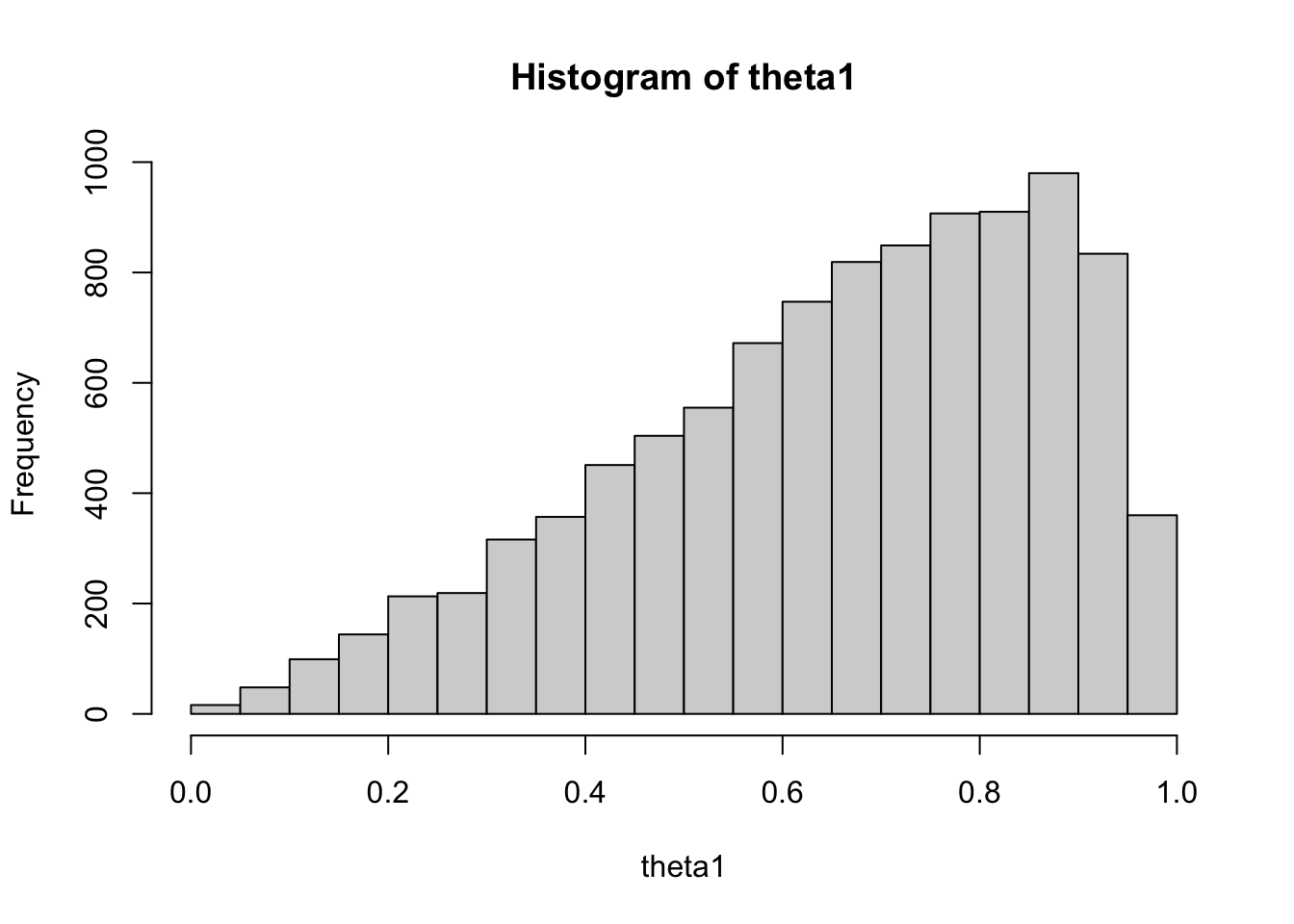
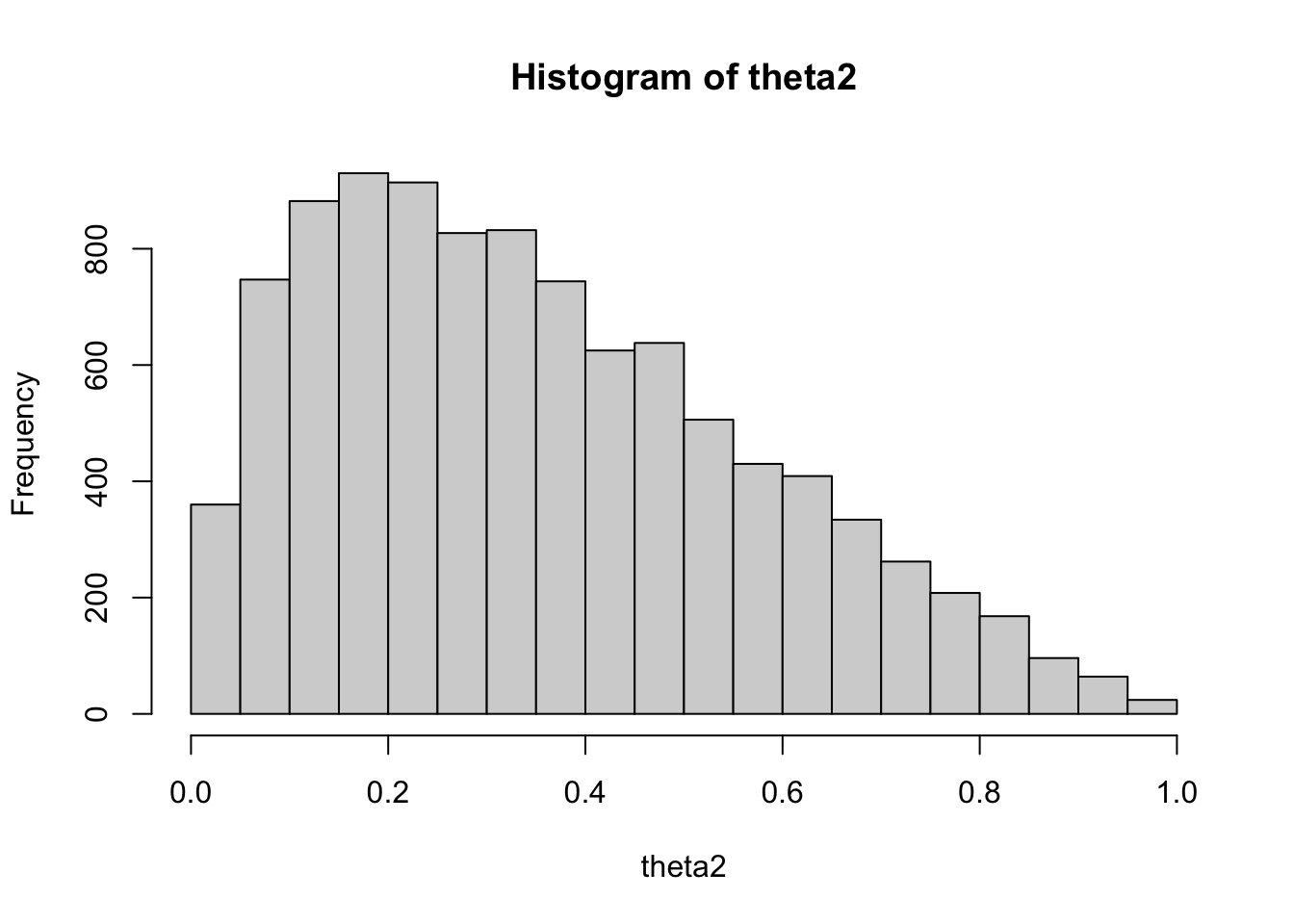
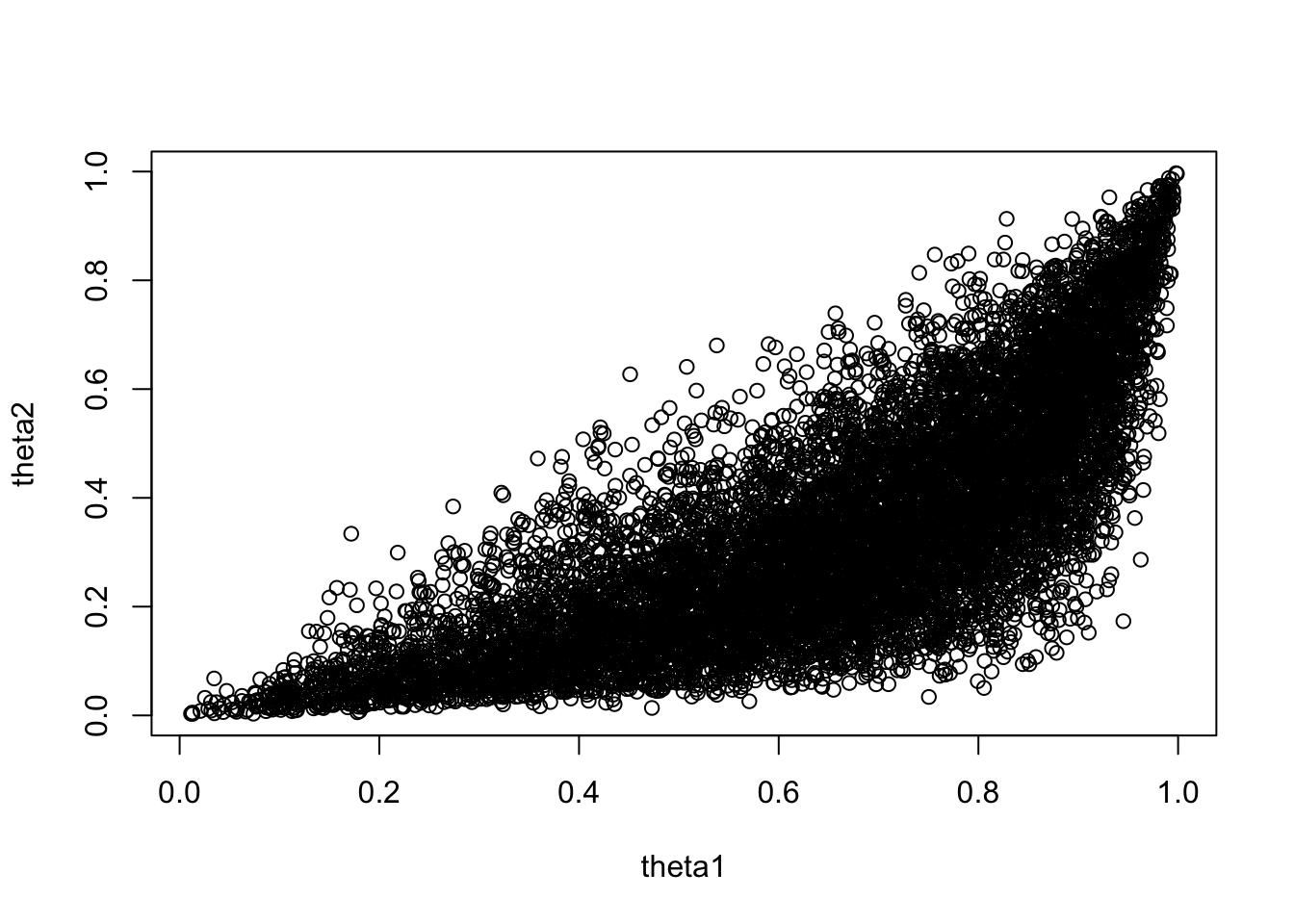
theta[1] 0.7743 0.1343 0.001900 0.002837
theta[2] 0.4982 0.1173 0.001659 0.002153
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
theta[1] 0.4591 0.6948 0.7982 0.8772 0.9673
theta[2] 0.2664 0.4178 0.4976 0.5813 0.7223
Warning in densfun(x, parm[1], parm[2], ...): NaNs produced
Warning in densfun(x, parm[1], parm[2], ...): NaNs produced
Warning in densfun(x, parm[1], parm[2], ...): NaNs produced
Warning in densfun(x, parm[1], parm[2], ...): NaNs produced
Warning in densfun(x, parm[1], parm[2], ...): NaNs produced
Warning in densfun(x, parm[1], parm[2], ...): NaNs produced
Iterations = 10001:15000
Thinning interval = 1
Number of chains = 1
Sample size per chain = 5000
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
0.0793840 0.0458026 0.0006477 0.0009964
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
0.01892 0.04646 0.07003 0.10131 0.19544
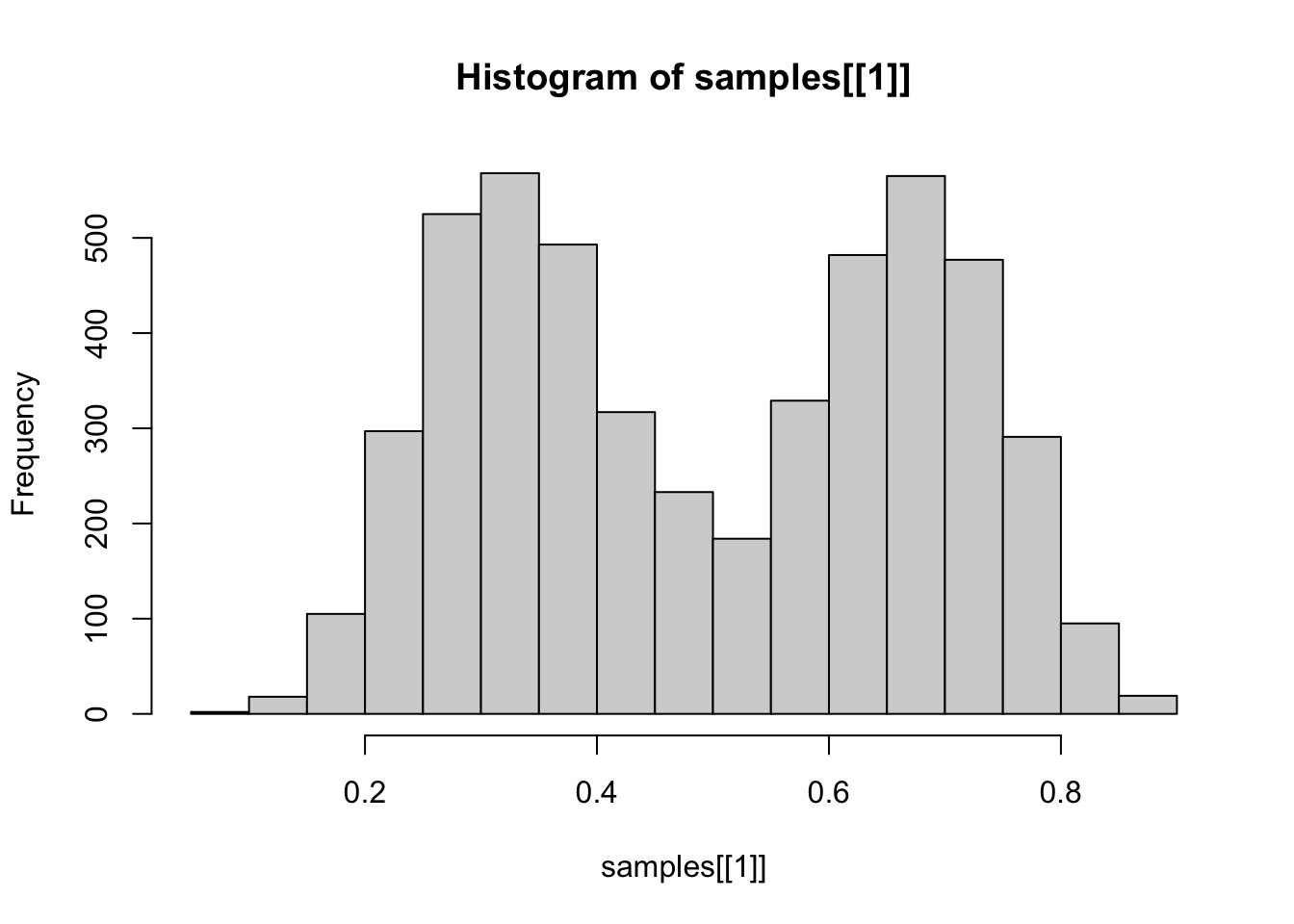
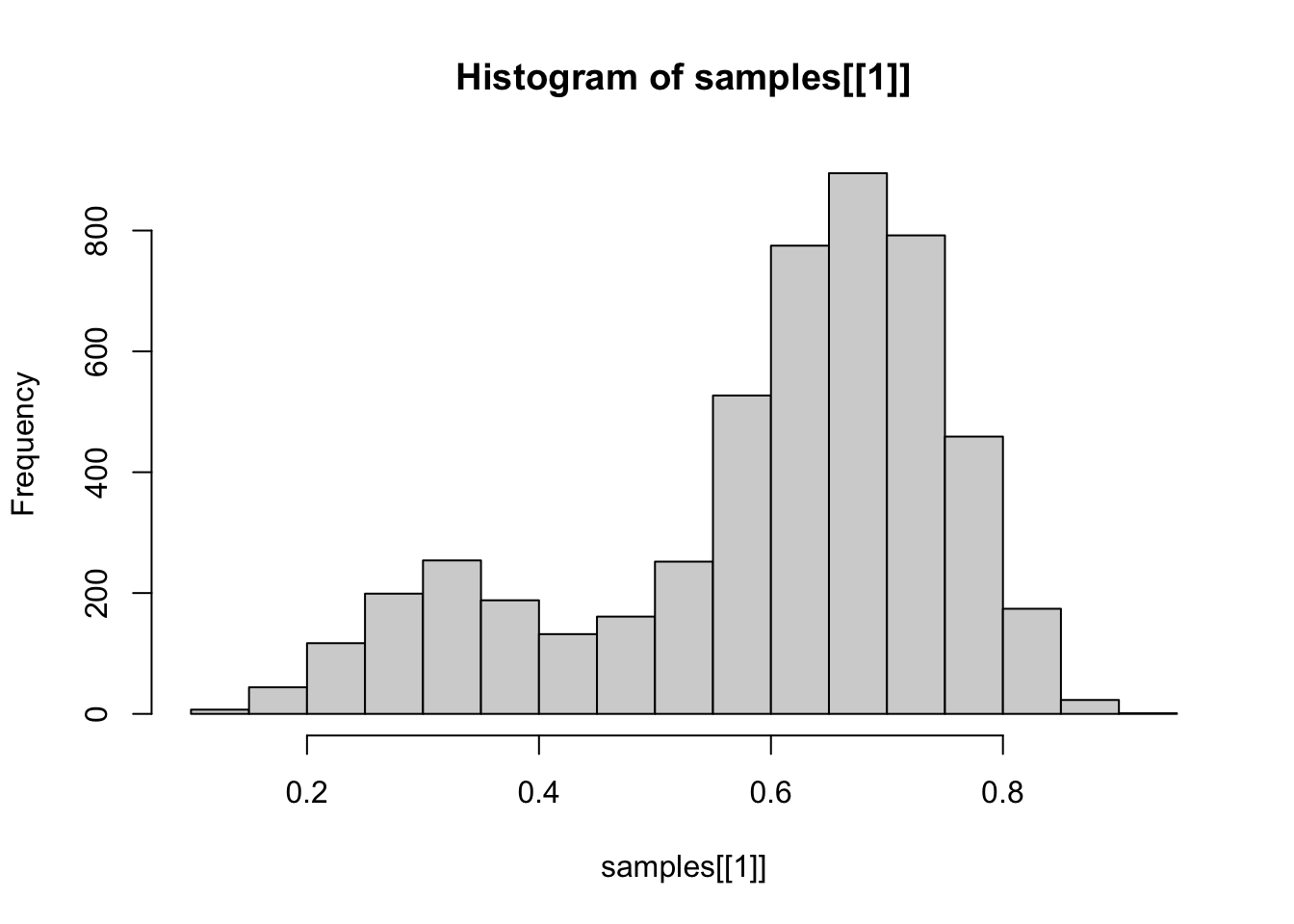
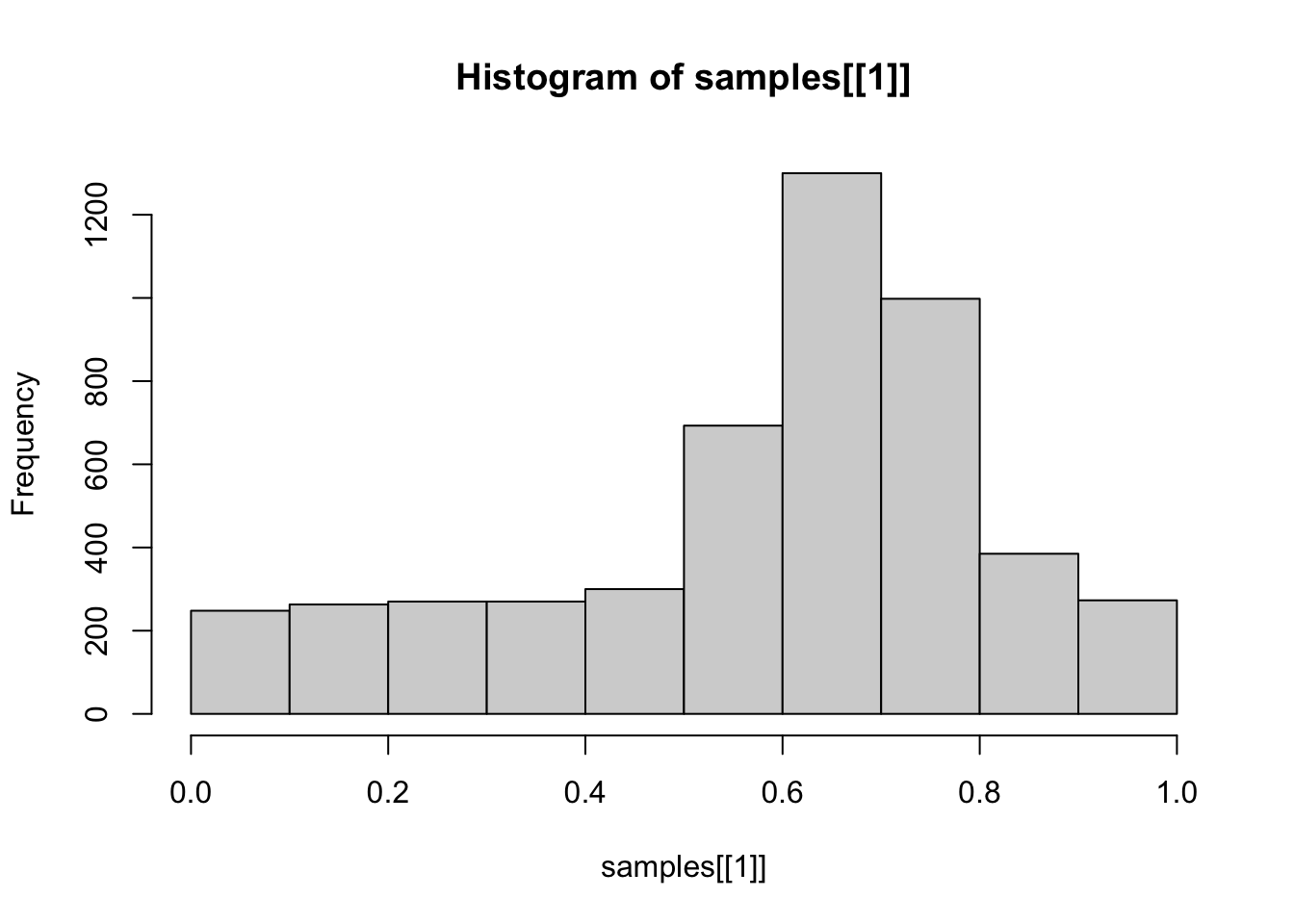
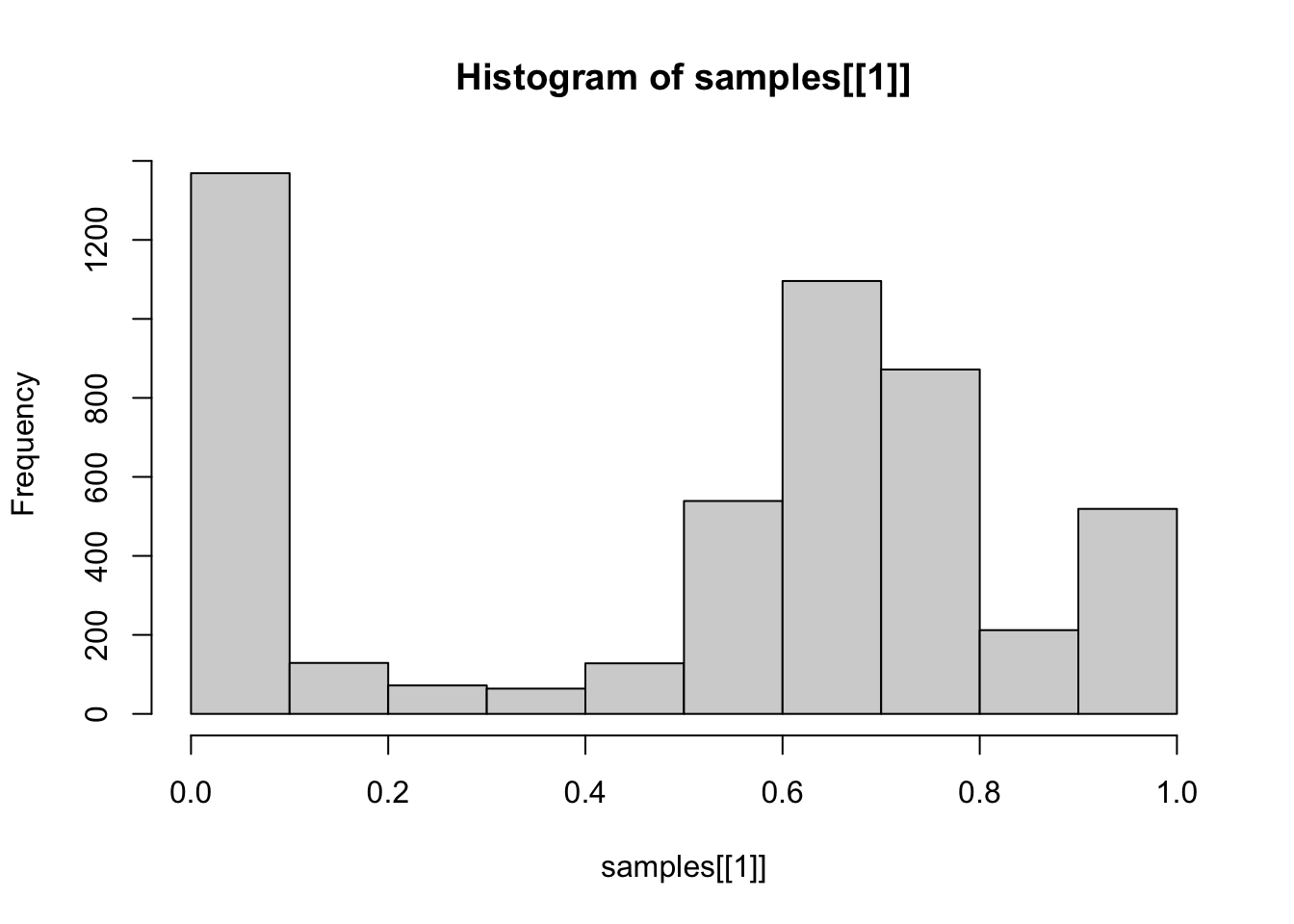
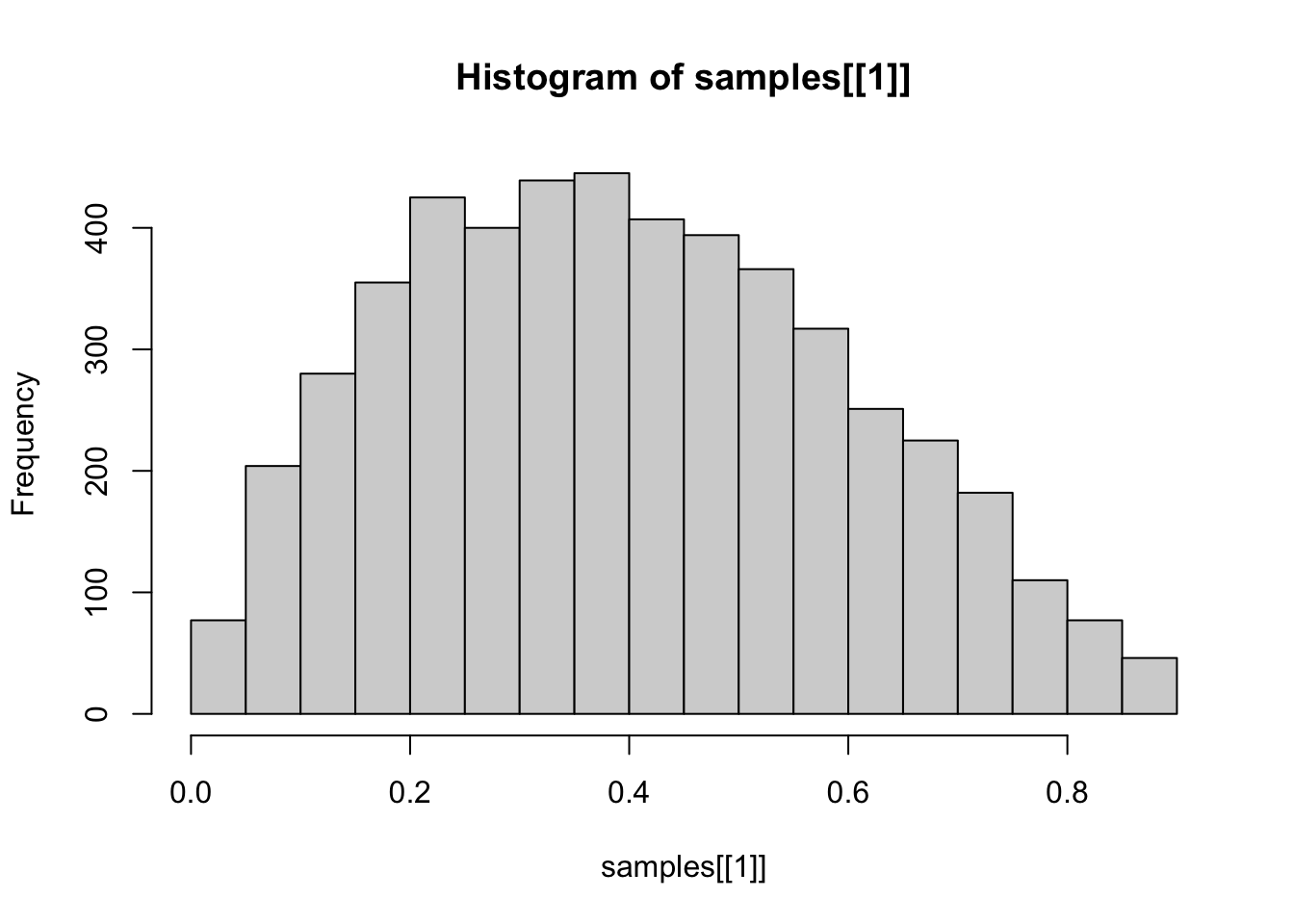
敏感性分析 换不同的先验 结果差不多
EXERCISE 5.23.
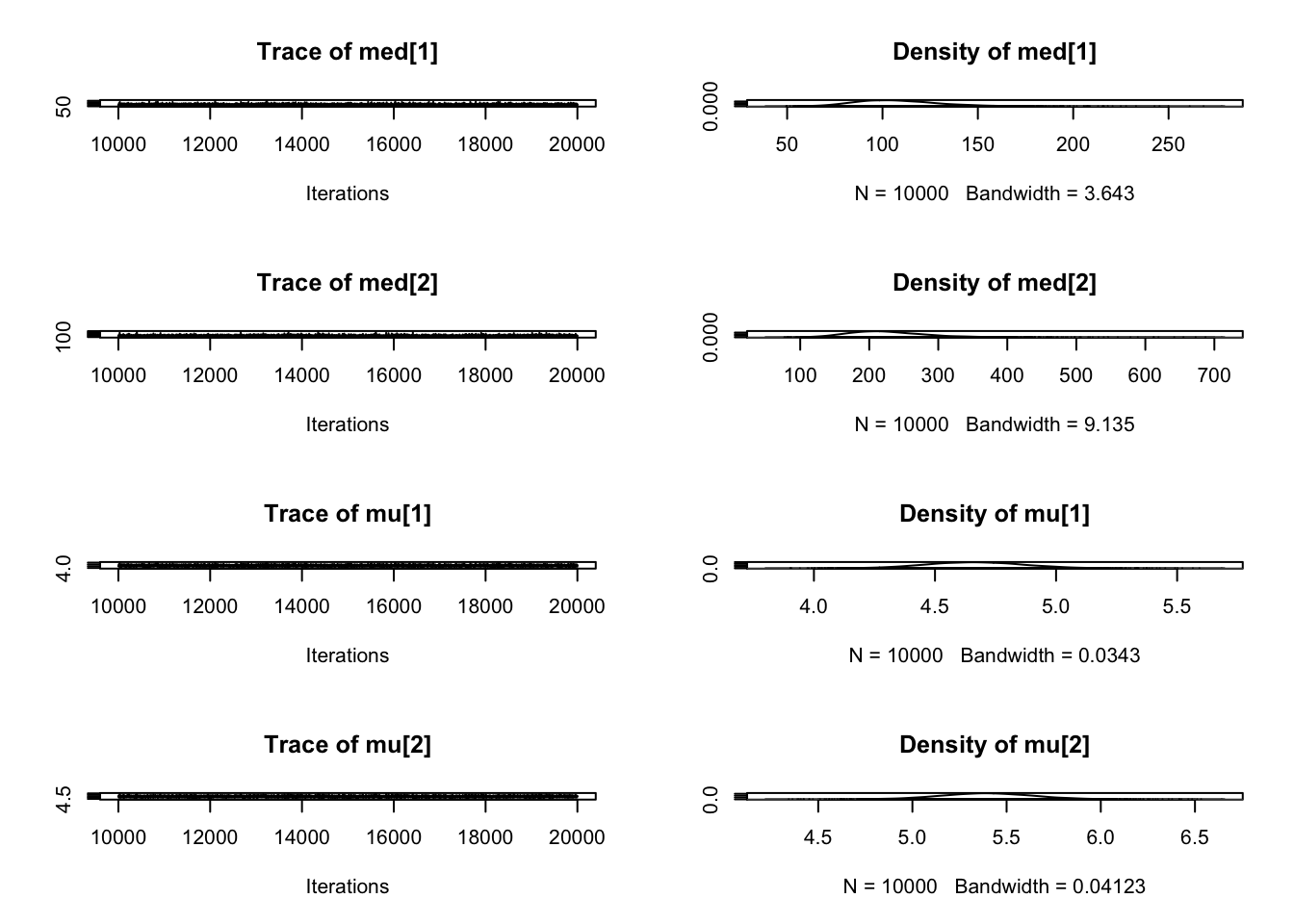
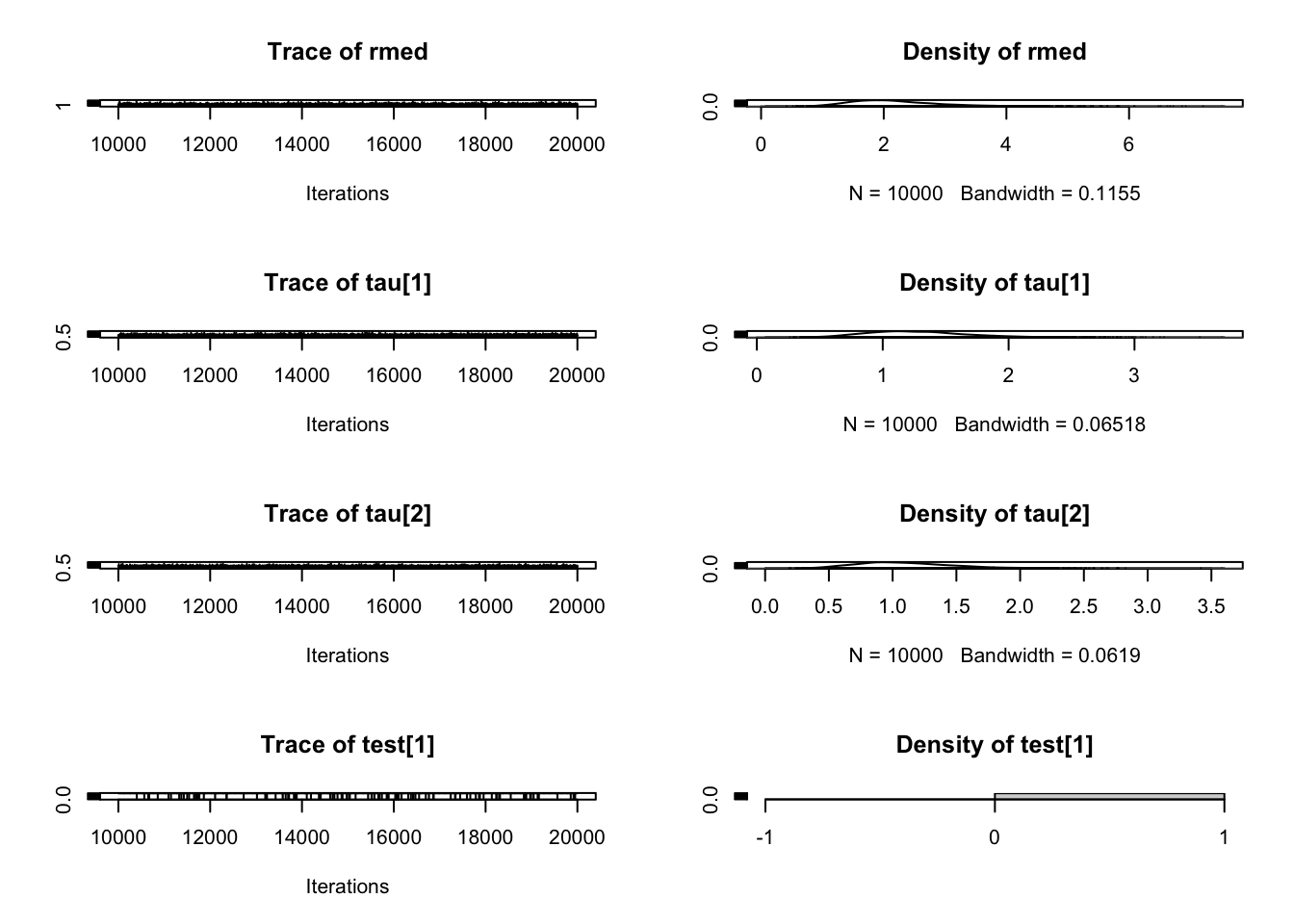
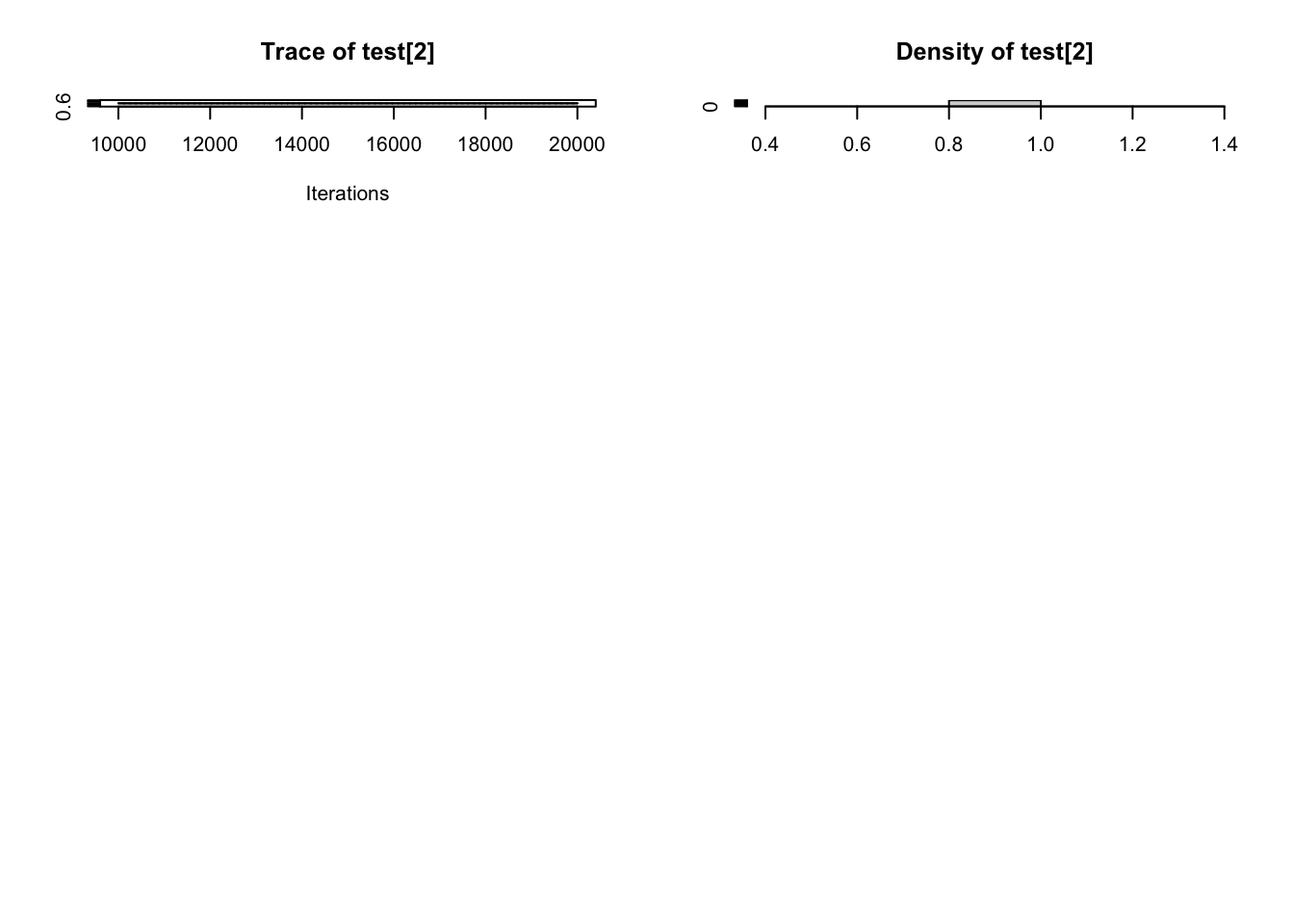
model_string <-"model{ for(i in 1:n){ y[i] ~ dnorm(mu, tau) } # 似然函数# mu ~ dflat() # 会报错 不能自动产生初始值# mu ~ dnorm(0, 1/1000000) mu ~ dnorm(4.75, 1/0.0163) tau ~ dgamma(c,d) sigma <- 1/sqrt(tau)gamma <- phi((4.4-mu)/sqrt(1/tau)) prob <- step(4.4 - y[13]) } "data_list <-list(y=c(4.20,4.36,4.11,3.96,5.63,4.50, 5.64,4.38,4.45,3.67,5.26,4.66,NA),c=0.001, d=0.001,n=13) jags_model <-jags.model(textConnection(model_string),data=data_list,n.chains=1,n.adapt =5000)
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 12
Unobserved stochastic nodes: 3
Total graph size: 32
Initializing model
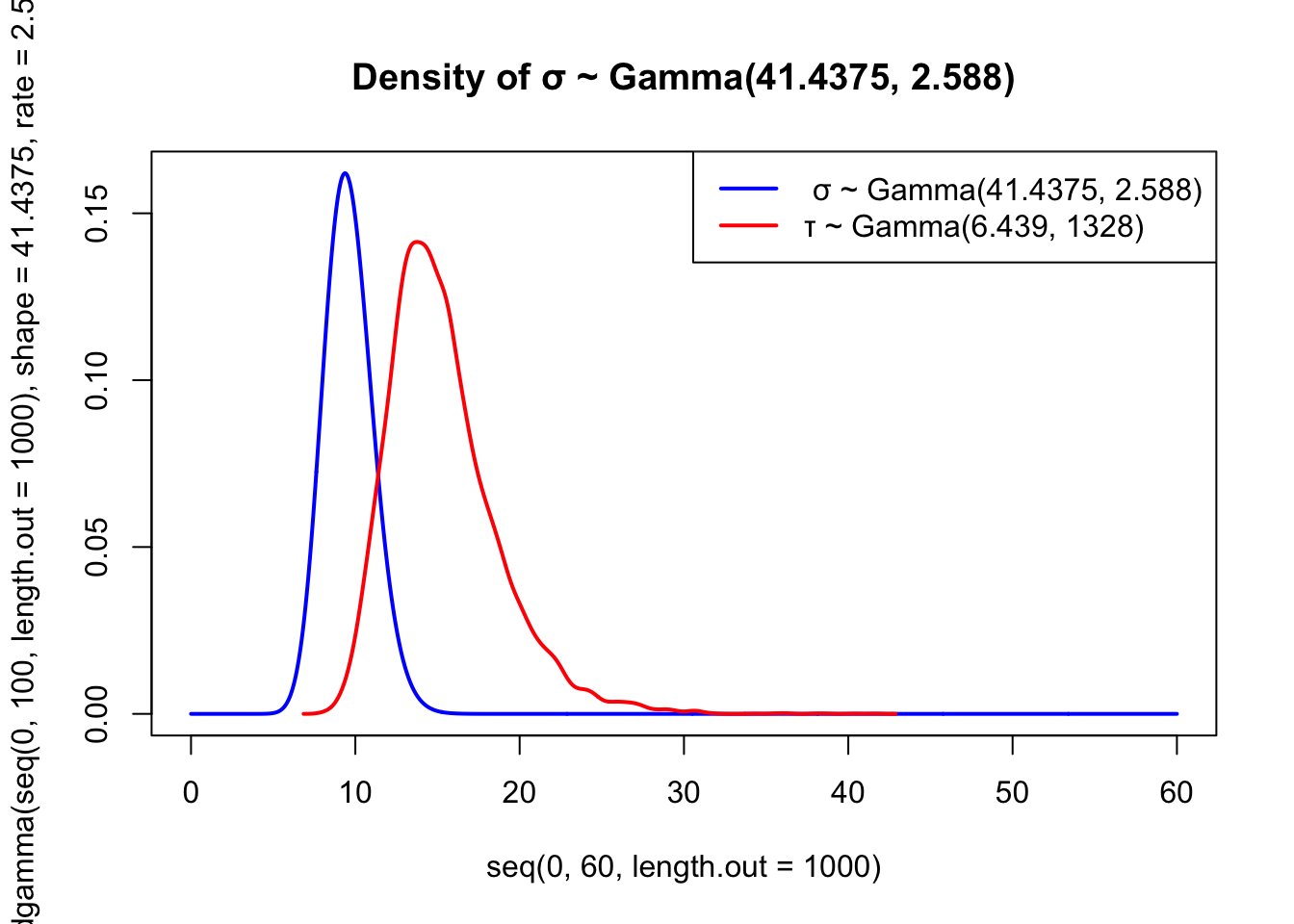
#1 R Code for finding prior on sigma alpha <-0.90beta <-0.95a <-65# Best guess for mu tildegamma <-85# Best guess for gamma_alphatildeu <-91# Best guess percentile of gamma_alpha zalpha <-1.28# qnorm(0.90,0,1) f <-2.588# Initial value for f # Could use a sequence of values, say f <- seq(1,50,1) sigma0 <- (tildegamma - a)/zalphae <-1+ sigma0*f # We must find the Gamma(e,f) distribution that# has beta-percentile = tildesigmabeta tildesigmabeta <- (tildeu - a)/zalpha trialq <-qgamma(beta,e,f) # Return beta-percentile for the # selected gamma distribution trialq # If trialq = tildesigmabeta
[1] 20.31031
tildesigmabeta # stop and pick corresponding f
[1] 20.3125
e
[1] 41.4375
f
[1] 2.588
#2 R Code for finding prior on tau alpha <-0.90beta <-0.95zalpha <-1.28a <-65tildegamma <-85tildel <-79# 最后一问这里改成70d <-1328tau0 = (zalpha/(tildegamma - a))^2c =1+ tau0*d tildetaubeta = (zalpha/(tildel - a))^2trialq =qgamma(beta,c,d) trialq
#1 R Code for finding prior on sigma alpha <-0.90beta <-0.95a <-60# Best guess for mu 改这里tildegamma <-85# Best guess for gamma_alphatildeu <-91# Best guess percentile of gamma_alpha zalpha <-1.28# qnorm(0.90,0,1) f <-3.068# Initial value for f # 二分法手调 懒得写函数了# Could use a sequence of values, say f <- seq(1,50,1) sigma0 <- (tildegamma - a)/zalphae <-1+ sigma0*f # We must find the Gamma(e,f) distribution that# has beta-percentile = tildesigmabeta tildesigmabeta <- (tildeu - a)/zalpha trialq <-qgamma(beta,e,f) # Return beta-percentile for the # selected gamma distribution trialq # If trialq = tildesigmabeta
[1] 24.21879
tildesigmabeta # stop and pick corresponding f
[1] 24.21875
e
[1] 60.92188
a=60u=70b <- (1.645/(u-a))^2b
[1] 0.02706025
Note
\(\mu ~ N(60, 1/0.02706025)\)
\(\sigma ~ Gamma(60.92188, 3.068)\)
you are 95% sure that the mean exam score is less than 65,
a=60u=65b <- (1.645/(u-a))^2b
[1] 0.108241
#1 R Code for finding prior on sigma alpha <-0.90beta <-0.95a <-60# Best guess for mu tildegamma <-85# Best guess for gamma_alphatildeu <-91# Best guess percentile of gamma_alpha zalpha <-1.28# qnorm(0.90,0,1) f <-3.068# Initial value for f # 二分法手调 懒得写函数了# Could use a sequence of values, say f <- seq(1,50,1) sigma0 <- (tildegamma - a)/zalphae <-1+ sigma0*f # We must find the Gamma(e,f) distribution that# has beta-percentile = tildesigmabeta tildesigmabeta <- (tildeu - a)/zalpha trialq <-qgamma(beta,e,f) # Return beta-percentile for the # selected gamma distribution trialq # If trialq = tildesigmabeta
[1] 24.21879
tildesigmabeta # stop and pick corresponding f
[1] 24.21875
e
[1] 60.92188
Note
\(\mu ~ N(60, 1/0.108241)\)
\(\sigma ~ Gamma(60.92188, 3.068)\)
your best guess for the 90th percentile of exam scores is 80, and
a=60u=65b <- (1.645/(u-a))^2b
[1] 0.108241
#1 R Code for finding prior on sigma alpha <-0.90beta <-0.95a <-60# Best guess for mu tildegamma <-80# Best guess for gamma_alphatildeu <-91# Best guess percentile of gamma_alpha zalpha <-1.28# qnorm(0.90,0,1) f <-0.932# Initial value for f # 二分法手调 懒得写函数了# Could use a sequence of values, say f <- seq(1,50,1) sigma0 <- (tildegamma - a)/zalphae <-1+ sigma0*f # We must find the Gamma(e,f) distribution that# has beta-percentile = tildesigmabeta tildesigmabeta <- (tildeu - a)/zalpha trialq <-qgamma(beta,e,f) # Return beta-percentile for the # selected gamma distribution trialq # If trialq = tildesigmabeta
[1] 24.21494
tildesigmabeta # stop and pick corresponding f
[1] 24.21875
e
[1] 15.5625
Note
\(\mu ~ N(60, 1/0.108241)\)
\(\sigma ~ Gamma(15.5625, 0.932)\)
you are 95% sure that the 90th percentile is less than 90
a=60u=65b <- (1.645/(u-a))^2b
[1] 0.108241
#1 R Code for finding prior on sigma alpha <-0.90beta <-0.95a <-60# Best guess for mu tildegamma <-80# Best guess for gamma_alphatildeu <-90# Best guess percentile of gamma_alpha zalpha <-1.28# qnorm(0.90,0,1) f <-1.089# Initial value for f # 二分法手调 懒得写函数了# Could use a sequence of values, say f <- seq(1,50,1) sigma0 <- (tildegamma - a)/zalphae <-1+ sigma0*f # We must find the Gamma(e,f) distribution that# has beta-percentile = tildesigmabeta tildesigmabeta <- (tildeu - a)/zalpha trialq <-qgamma(beta,e,f) # Return beta-percentile for the # selected gamma distribution trialq # If trialq = tildesigmabeta